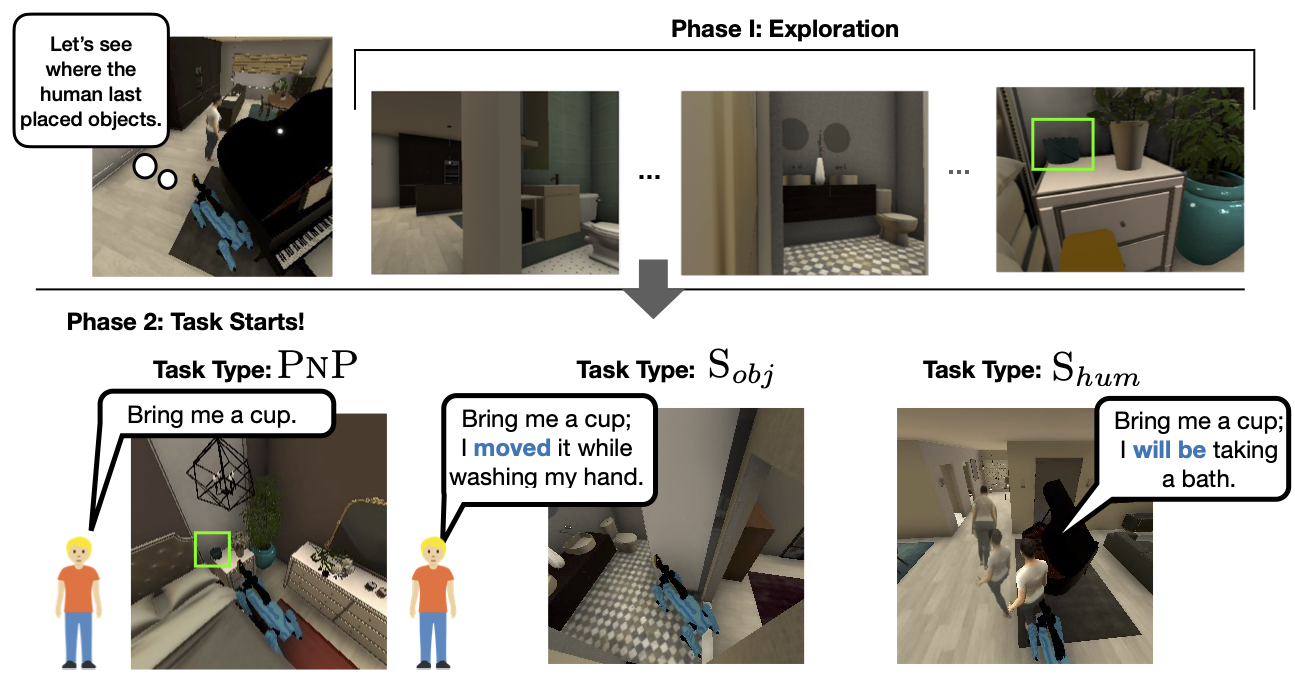
Humans naturally engage in communication that is ambiguous and contextually situated, providing just enough information as necessary. For instance, the instruction "Can you bring me a cup?"" can vary in meaning depending on the context. If spoken while the speaker is donning rubber gloves by the kitchen sink, it likely refers to a dirty cup located on the living room table. Conversely, the same request made in front of the bathroom sink typically implies a need for a clean cup. While it's possible to seek clarification, humans generally interpret and respond to such requests accurately without additional information. This capability demonstrates how humans skillfully use environmental and actional cues to interpret ambiguous language, crafting meanings that are intricately nuanced and context-specific.
However, current instruction-following tasks prioritize accurate low-level instruction interpretation (e.g. VLN) or use commonsense to achieve underspecified goals like object navigation. We present Situated Instruction Following (SIF), which generalizes Embodied Instruction Following to situated language - the natural language spoken by humans.
Task
The tasks in SIF consist of two phases: an exploration phase (phase 1) and a task phase (phase 2). PnP represents a conventional static Pick-and-Place task used for comparison, wherein the environment remains unchanged after the exploration phase. S_hum and S_obj introduce two novel types of situated instruction following tasks. In these tasks, the objets and human subjects move during the task phase. Nuanced communication regarding these movements is provided, necessitating reasoning about ambiguous, temporally evolving, and dynamic human intent.
Method
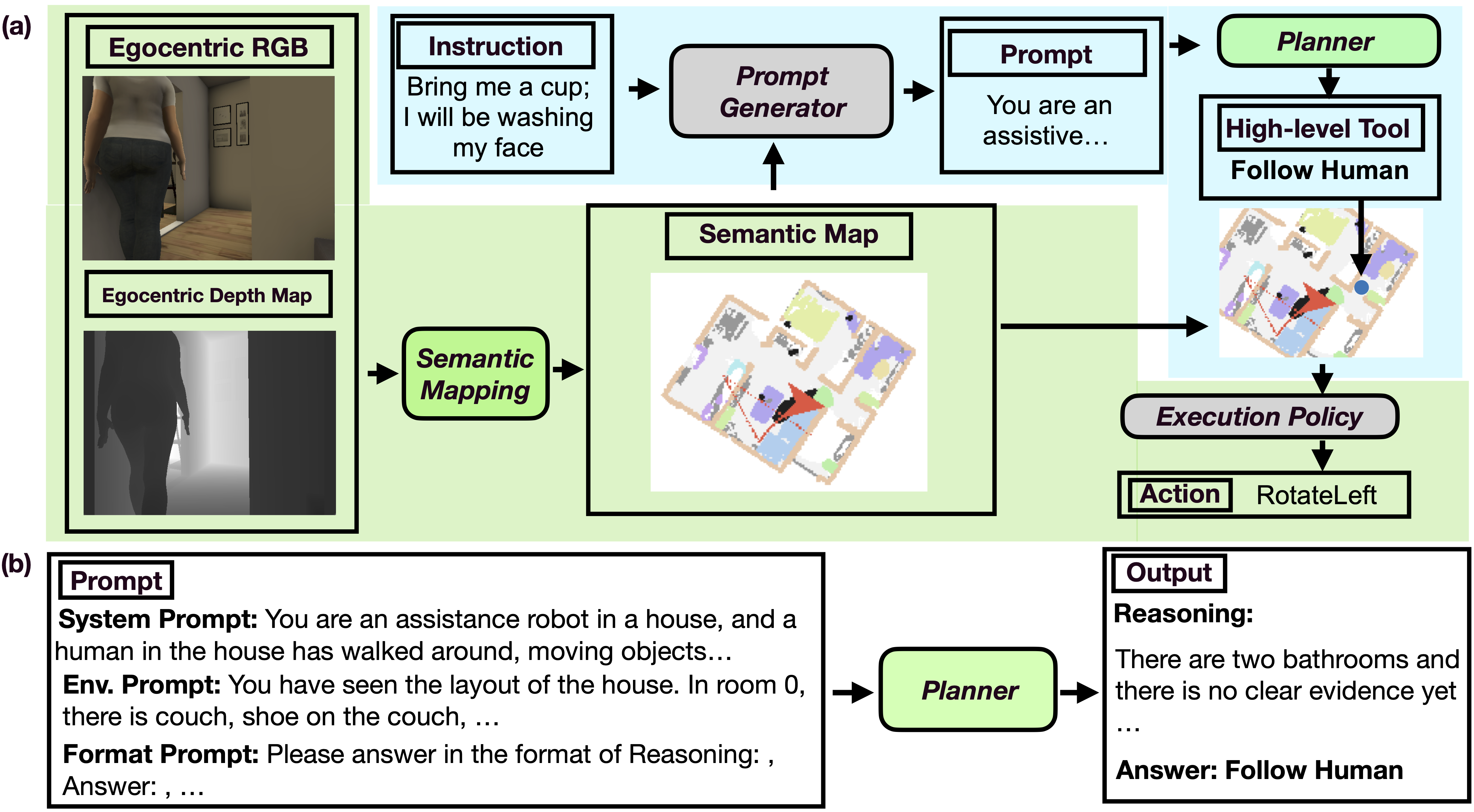
Above, we show Reasoner, a baseline we implemented by combining popular SOTA methods such as FILM, LLM-Planner, and ReAct. It operates through three main components: (1) a semantic mapper that updates an allocentric map from egocentric RGB and depth inputs, (2) a prompt generator that represents prompts, and (3) the planner (GPT-4o) that generates high-level actions. The semantic mapper is called every timestep, whereas the prompt generator and planner are activated upon completion of the last high-level action or when a new decision is required. We additionally implement Prompter, an existing SOTA model for ALFRED.
Results and Challenges
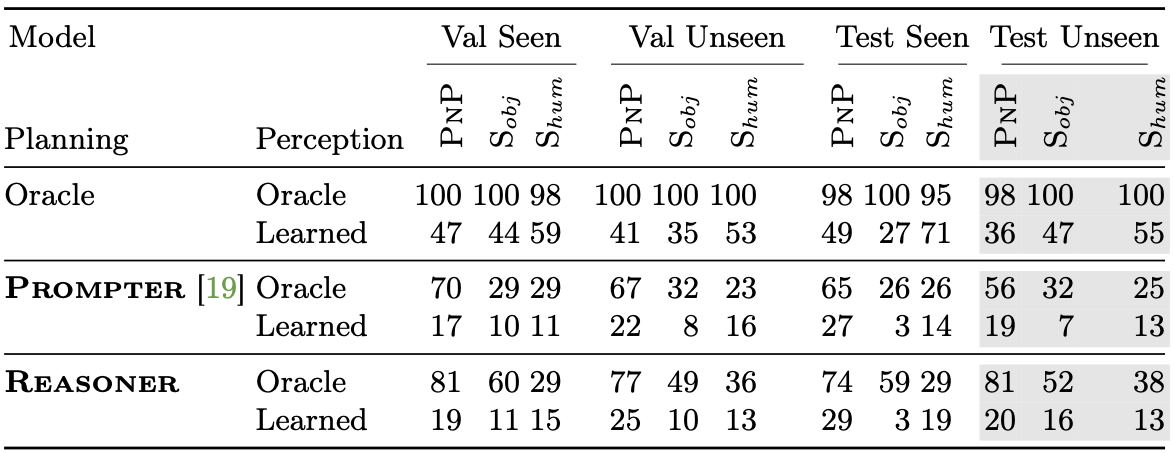
We show SPL performance of Reasoner and Prompter on SIF tasks. This table shows that S_obj and S_hum tasks are challenging to both models. In a more detailed analysis, we find that both Reasoner and Prompter struggle in navigating through ambiguity in instructions.
Paper and Bibtex
 [Paper]
[Paper]
|
|
Citation
Min, S., Puig, X., Chaplot, D., Yang, T., Rai, A., Parashar, P., Salakhutdino, R., Bisk, Y., Mottaghi, R. (2024).
Situated Instruction Following.
@inproceedings{min2024situatedinstructionfollowing,
title={Situated Instruction Following},
author={So Yeon Min and Xavi Puig and Devendra Singh Chaplot and Tsung-Yen Yang
and Akshara Rai and Priyam Parashar and Ruslan Salakhutdinov and Yonatan Bisk
and Roozbeh Mottaghi},
booktitle={ECCV},
year={2024},
}
|
|
|
|
|