FILM: Following Instructions in Language
with Modular Methods

|
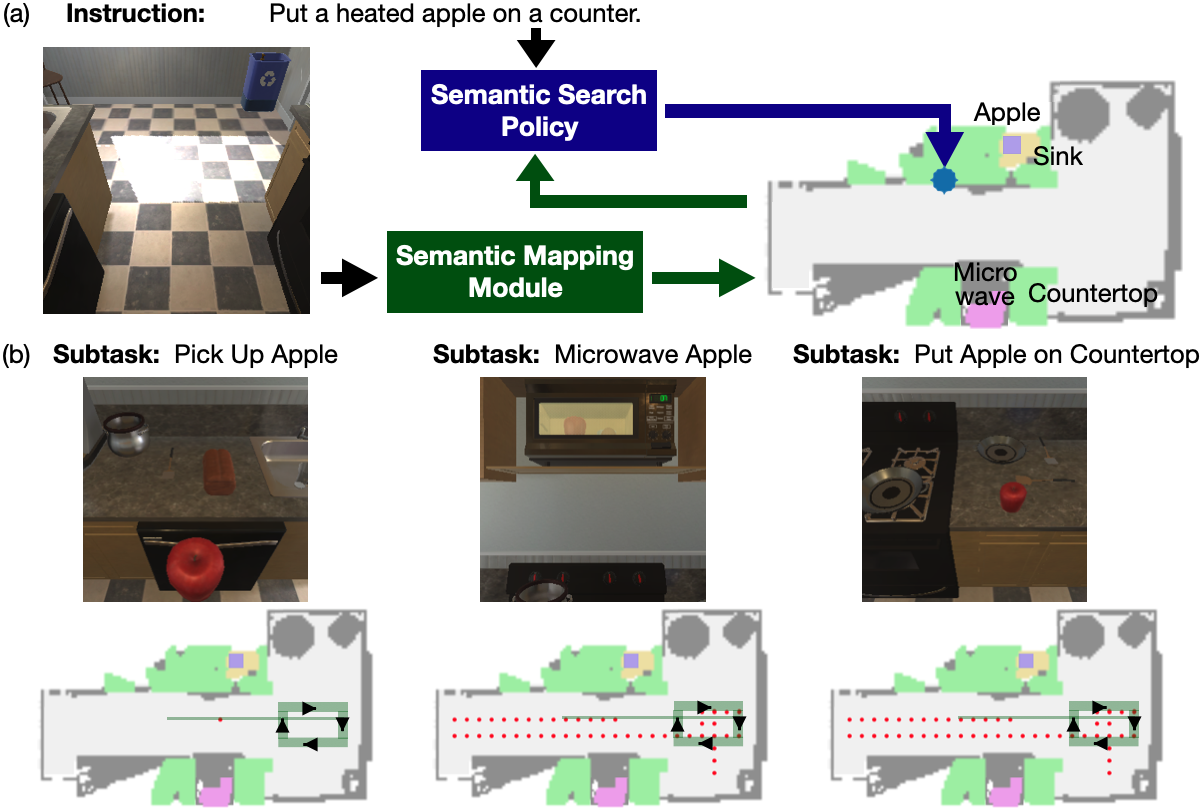
Recent methods for embodied instruction following are typically trained end-to- end using imitation learning. This requires the use of expert trajectories and low- level language instructions. Such approaches assume learned hidden states will simultaneously integrate semantics from the language and vision to perform state tracking, spatial memory, exploration, and long-term planning. In contrast, we propose a modular method with structured representations that (1) builds a semantic map of the scene, and (2) performs exploration with a semantic search policy, to achieve the natural language goal. Our modular method achieves SOTA performance (24.46%) with a substantial (8.17 % absolute) gap from previous work while using less data by eschewing both expert trajectories and low-level instructions. Leveraging low-level language, however, can further increase our performance (26.49%). Our findings suggest that an explicit spatial memory and a semantic search policy can provide a stronger and more general representation for state-tracking and guidance, even in the absence of expert trajectories or low- level instructions.
FILM
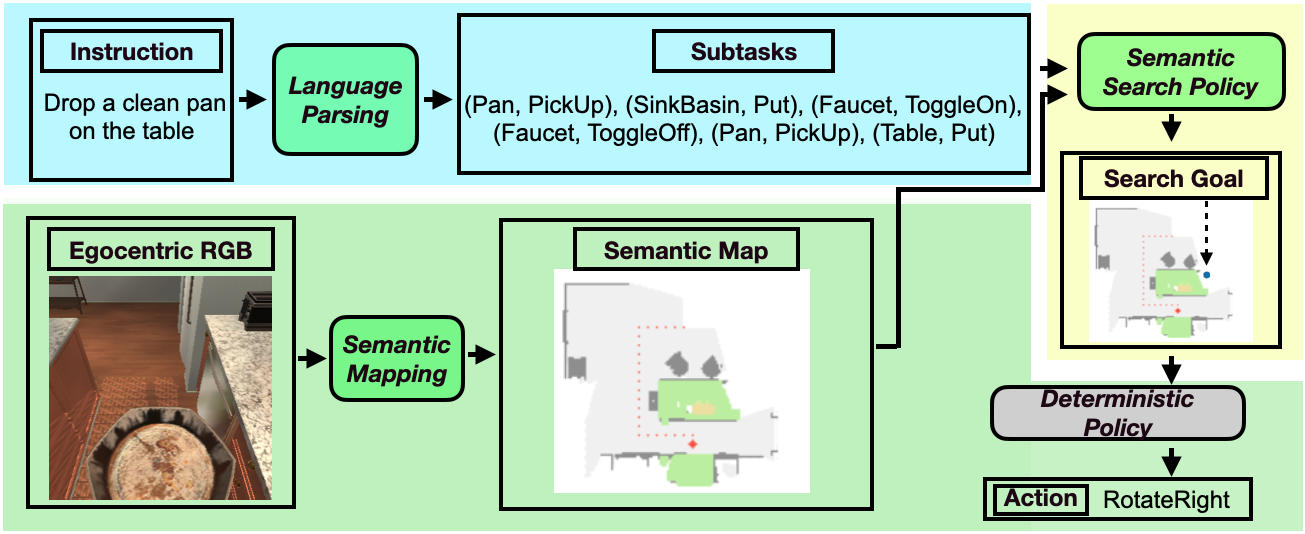
FILM consists of three learned modules: (1) Language Processing (LP), (2) Semantic Mapping, and (3) Semantic Search Policy; and one purely deterministic navigation/ interaction policy module. At the start of an episode, the LP module processes the language instruction into a sequence of subtasks. Every time step, the semantic mapping module receives the egocentric RGB frame and updates the semantic map. If the goal object of the current subtask is not yet observed, the semantic search policy predicts a “search goal” at a coarse time scale; until the next search goal is predicted, the agent navigates to the current search goal with the deterministic policy. If the goal is observed, the deterministic policy decides low-level controls for interaction actions (e.g. “Pick Up” object).
Source Code and Pre-trained models
The code and pretrained models (BERT for ALFRED/ Semantic Segmentation (Mask-RCNN) for AI2THOR ALFRED splits/ Depth model for AI2THOR ALFRED splits) are all released
[here]
Paper and Bibtex
 [Paper]
[Paper]
|
|
Citation
Min, S., Chaplot, D.S., Ravikumar, P., Bisk, Y. and Salakhutdinov, R. (2021).
FILM: Following Instructions in Language with Modular Methods.
ArXiv, abs/2107.05612.
[Bibtex]
@misc{min2021film,
title={FILM: Following Instructions in Language with Modular Methods},
author={So Yeon Min and Devendra Singh Chaplot and Pradeep Ravikumar and Yonatan Bisk and Ruslan Salakhutdinov},
year={2021},
eprint={2110.07342},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
|
|
|
|
|